innodb_large_prefix对查询性能的影响
前段时间在生产环境遇到个生产问题,开发反应业务系统响应时间很慢,CPU使用率达到百分之百,严重影响到了业务
问题排查
CPU百分之百,首先想到了慢SQL,将慢SQL取出,发现当天慢SQL文件多达60几个(RDS云环境,自己做了分割),查看文件发现出现大量相同的SQL语句
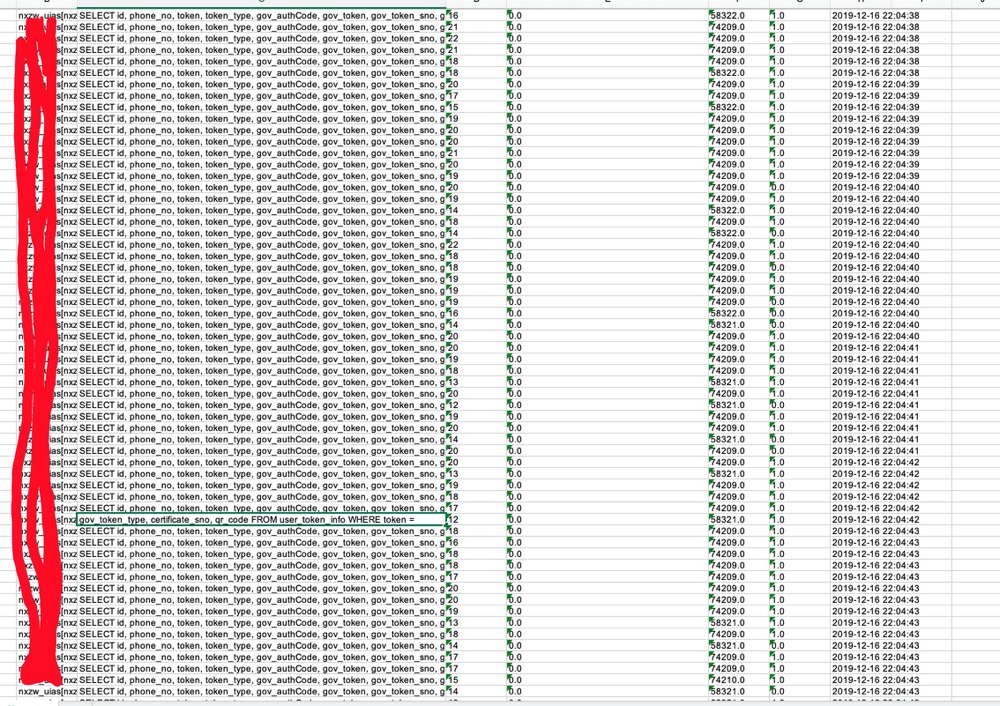
这个SQ是用在登录认证, 根据token查询用户信息,按理说这种查询理论上应该效率是非常高的,查看了执行计划如下:
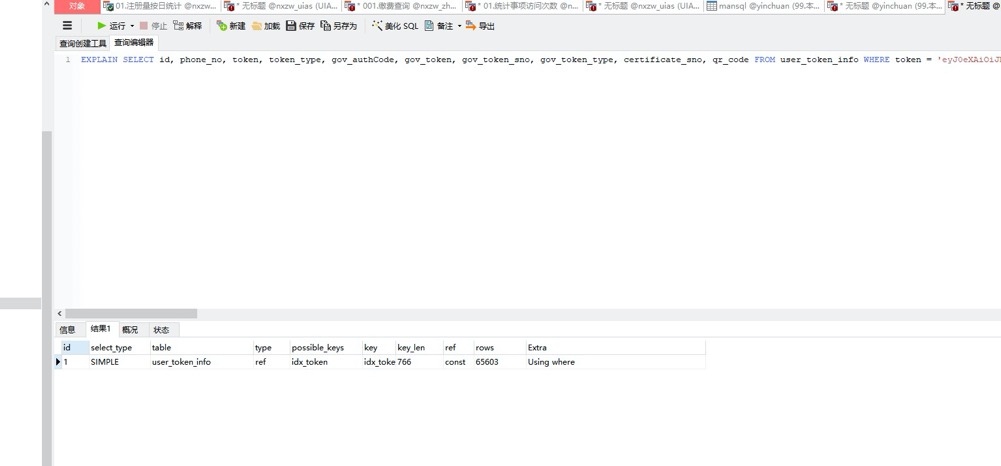
通过执行计划我们看到了,rows扫描行数还是比较多,跟想象的还是有差距,我们认为应该是根据token唯一定位到某条记录,扫描的行数应该是很少的。
查看表结构,发现token这个字段类型是varchar(4000),默认情况下innodb下创建的索引最大长度是767字节,大概原因我们就知道了,由于字段长度过长,导致创建索引的长度有限,这样实际索引的区分度就非常低了,每次查询都要扫描很多的行,加上这个查询是一个高频的查询,导致了系统运行缓慢。
问题解决
这个问题有几种解决方式:
第一种:
修改数据库参数innodb_large_prefix设置为on,这样可以将创建索引的长度扩大到3072,这样可以提高索引数据的区分度,每次查询时扫描的行数就会降低。当天晚上修改了此参数后,查看执行计划rows扫描的行数就降至到了95,并且第二天也无此SQL的慢查询,慢查询日志文件也从前一天的60个文件较少到了1个第二种:
通过增加缓存的方式,将token放到缓存中,减少对数据库的访问次数