/* NOTE: the system columns MUST be added in the following order (so that they can be indexed by the numerical value of DATA_ROW_ID, etc.) and as the last columns of the table memory object. The clustered index will not always physically contain all system columns. Intrinsic table don't need DB_ROLL_PTR as UNDO logging is turned off for these tables. */
/* This check reminds that if a new system column is added to the program, it should be dealt with here */ #if DATA_N_SYS_COLS != 3 #error "DATA_N_SYS_COLS != 3" #endif } }
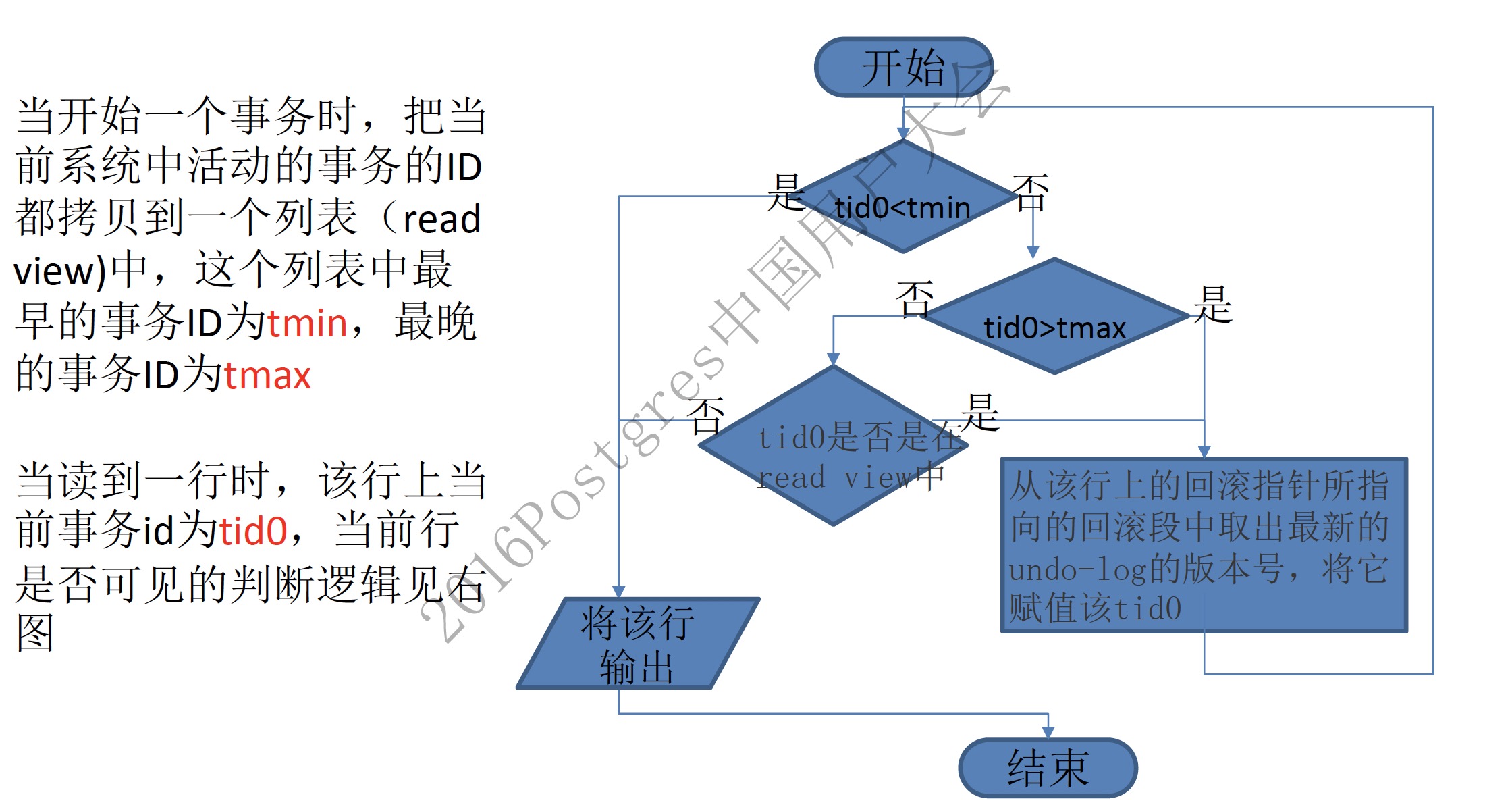
/** The read should not see any transaction with trx id >= this value. In other words, this is the "high water mark". */ trx_id_t m_low_limit_id;
/** The read should see all trx ids which are strictly smaller (<) than this value. In other words, this is the low water mark". */ trx_id_t m_up_limit_id;
/** trx id of creating transaction, set to TRX_ID_MAX for free views. */ trx_id_t m_creator_trx_id;
函数row_search_mvcc->lock_clust_rec_cons_read_sees bool lock_clust_rec_cons_read_sees( /*==========================*/ const rec_t* rec, /*!< in: user record which should be read or passed over by a read cursor */ dict_index_t* index, /*!< in: clustered index */ const ulint* offsets,/*!< in: rec_get_offsets(rec, index) */ ReadView* view) /*!< in: consistent read view */ { ut_ad(index->is_clustered()); ut_ad(page_rec_is_user_rec(rec)); ut_ad(rec_offs_validate(rec, index, offsets));
/* Temp-tables are not shared across connections and multiple transactions from different connections cannot simultaneously operate on same temp-table and so read of temp-table is always consistent read. */ //只读事务或者临时表是不需要一致性读的判断 if (srv_read_only_mode || index->table->is_temporary()) { ut_ad(view == 0 || index->table->is_temporary()); return(true); }
/* NOTE that we call this function while holding the search system latch. */