Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.
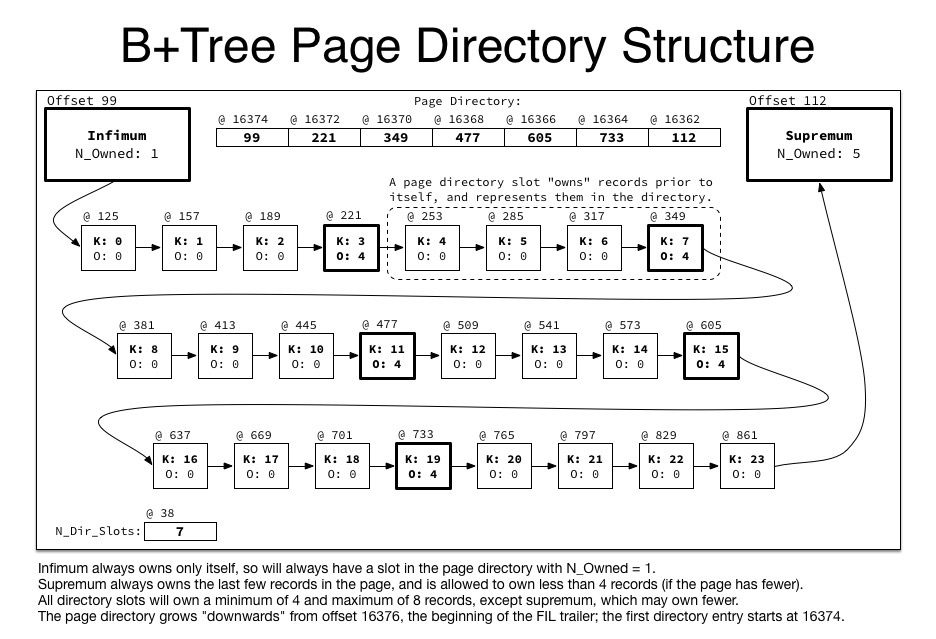
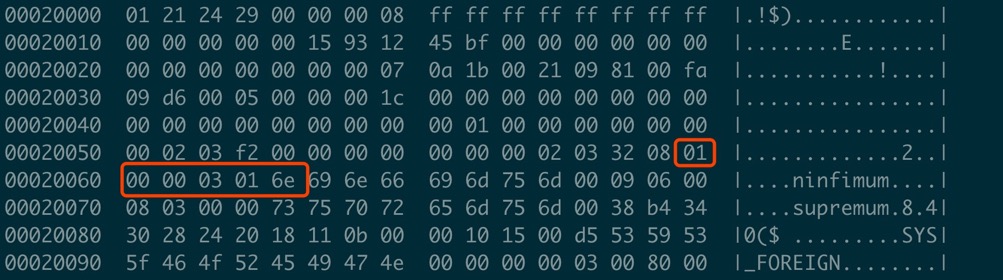
上面这两张图中Nmuber of Directory Slots和Page Directory比较重要,Slots的作用是加快在页面内数据的查找速度,实现二分查找,通过解析Nmuber of Directory Slots可以得到page中总共有多少Slot,每个Slot为2个字节,存放相对于page的偏移量。
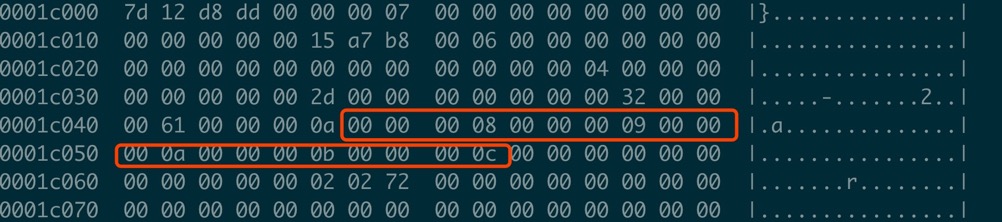
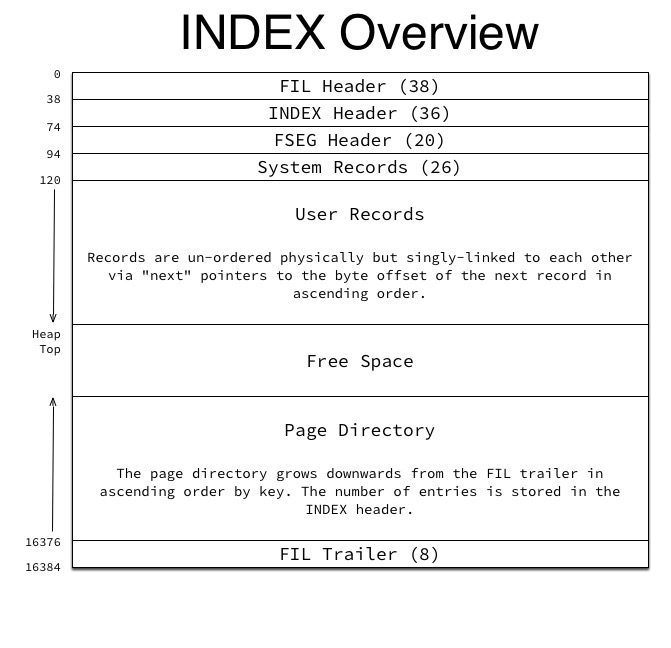
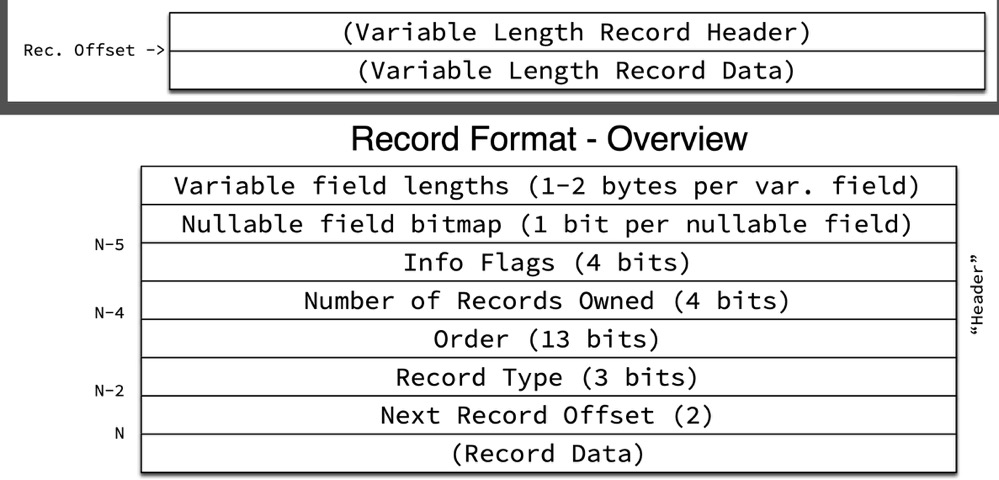
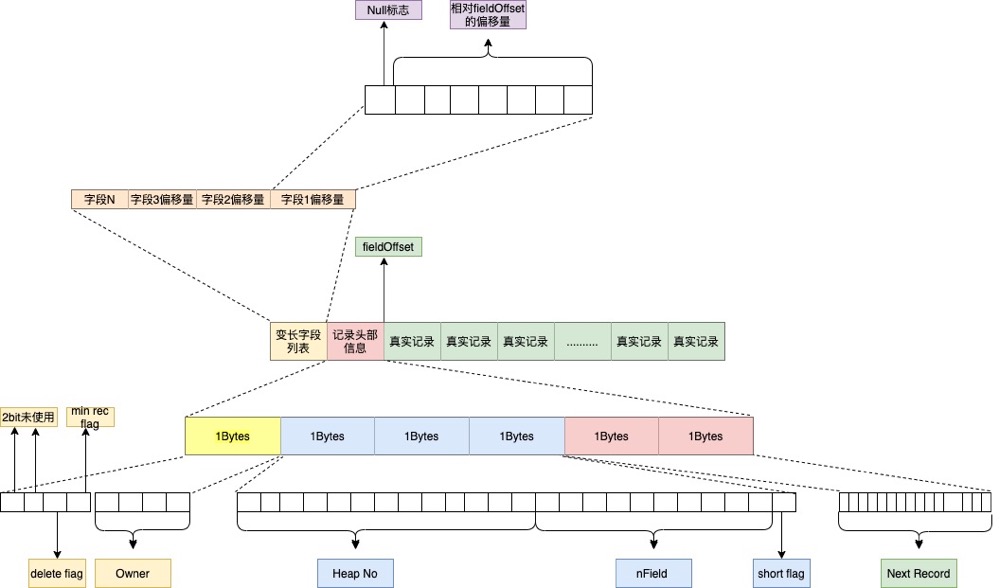
现在知道了如何通过Page Directory定位数据,就需要知道每一条记录的存储结构了, MySQL 记录格式有新旧两种(Redundant Or Compact),Index Header 中Number of Heap Records 的最高位如果是1就是Compact格式,否则是Redundant。
(storage/innobase/include/page0page.h)
1 2 3 4
#define PAGE_N_HEAP 4 /* number of records in the heap, bit 15=flag: new-style compact page format */
/* Offsets of the bit-fields in an old-style record. NOTE! In the table the most significant bytes and bits are written below less significant. (1) byte offset (2) bit usage within byte downward from origin -> 1 8 bits pointer to next record 2 8 bits pointer to next record 3 1 bit short flag 7 bits number of fields 4 3 bits number of fields 5 bits heap number 5 8 bits heap number 6 4 bits n_owned 4 bits info bi */
通过这些额外信息可以得到:
当前记录是否为delete记录
当前Slot中有几条记录
当前记录的类型, 如果heap number 为0是infimum,1是supremum,从2开始是用户记录
mysql> set global innodb_stats_auto_recalc = off; //关闭统计信息持久化收集
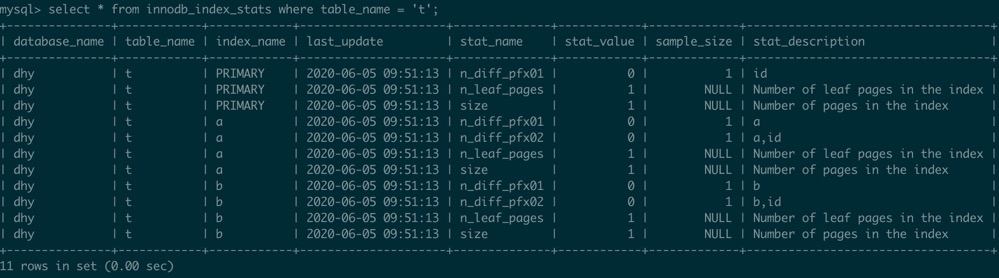
这时对应的统计信息如下:
再次插入数据
1 2 3 4
mysql> call idata();
Query OK, 1 row affected (5 min 10.59 sec)
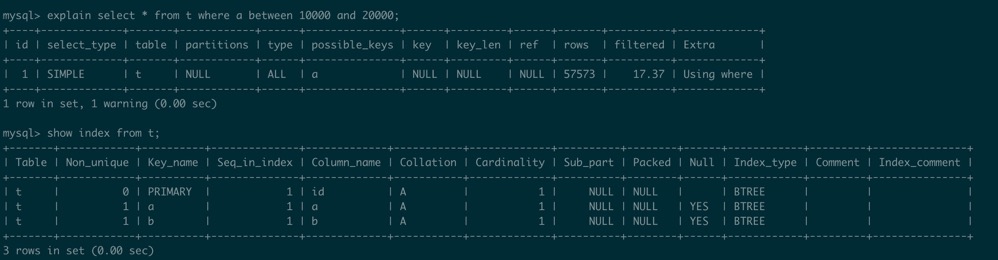
这时再执行相同的查询,就会看到走不到索引了:
导入统计信息
将原有的统计信息删除,并导入备份出来的统计信息
1 2 3 4 5 6 7 8 9 10 11 12
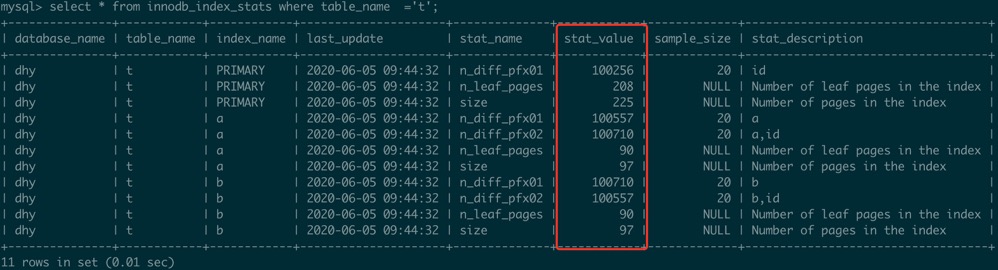
mysql> delete from innodb_index_stats where table_name = 't'; Query OK, 11 rows affected (0.01 sec)
mysql> INSERT INTO innodb_index_stats VALUES ('dhy','t','PRIMARY','2020-06-05 09:44:32','n_diff_pfx01',100256,20,'id'),('dhy','t','PRIMARY','2020-06-05 09:44:32','n_leaf_pages',208,NULL,'Number of leaf pages in the index'),('dhy','t','PRIMARY','2020-06-05 09:44:32','size',225,NULL,'Number of pages in the index'),('dhy','t','a','2020-06-05 09:44:32','n_diff_pfx01',100557,20,'a'),('dhy','t','a','2020-06-05 09:44:32','n_diff_pfx02',100710,20,'a,id'),('dhy','t','a','2020-06-05 09:44:32','n_leaf_pages',90,NULL,'Number of leaf pages in the index'),('dhy','t','a','2020-06-05 09:44:32','size',97,NULL,'Number of pages in the index'),('dhy','t','b','2020-06-05 09:44:32','n_diff_pfx01',100710,20,'b'),('dhy','t','b','2020-06-05 09:44:32','n_diff_pfx02',100557,20,'b,id'),('dhy','t','b','2020-06-05 09:44:32','n_leaf_pages',90,NULL,'Number of leaf pages in the index'),('dhy','t','b','2020-06-05 09:44:32','size',97,NULL,'Number of pages in the index');
Query OK, 11 rows affected (0.00 sec)
Records: 11 Duplicates: 0 Warnings: 0
同时需要把innodb_table_stats表中的n_rows修改为10万
mysql> update innodb_table_stats set n_rows = 100000 where table_name = 't';
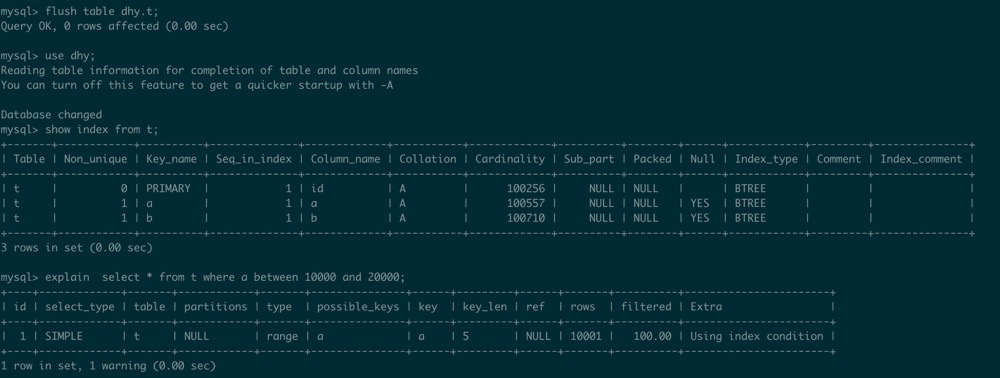
导入之后直接执行语句,还是走不到索引,通过show index from t;可以看到索引的统计信息还没有更新,需要执行一次flush table(线上谨慎执行或者不建议操作),将统计信息从持久化磁盘上刷新到内存中。
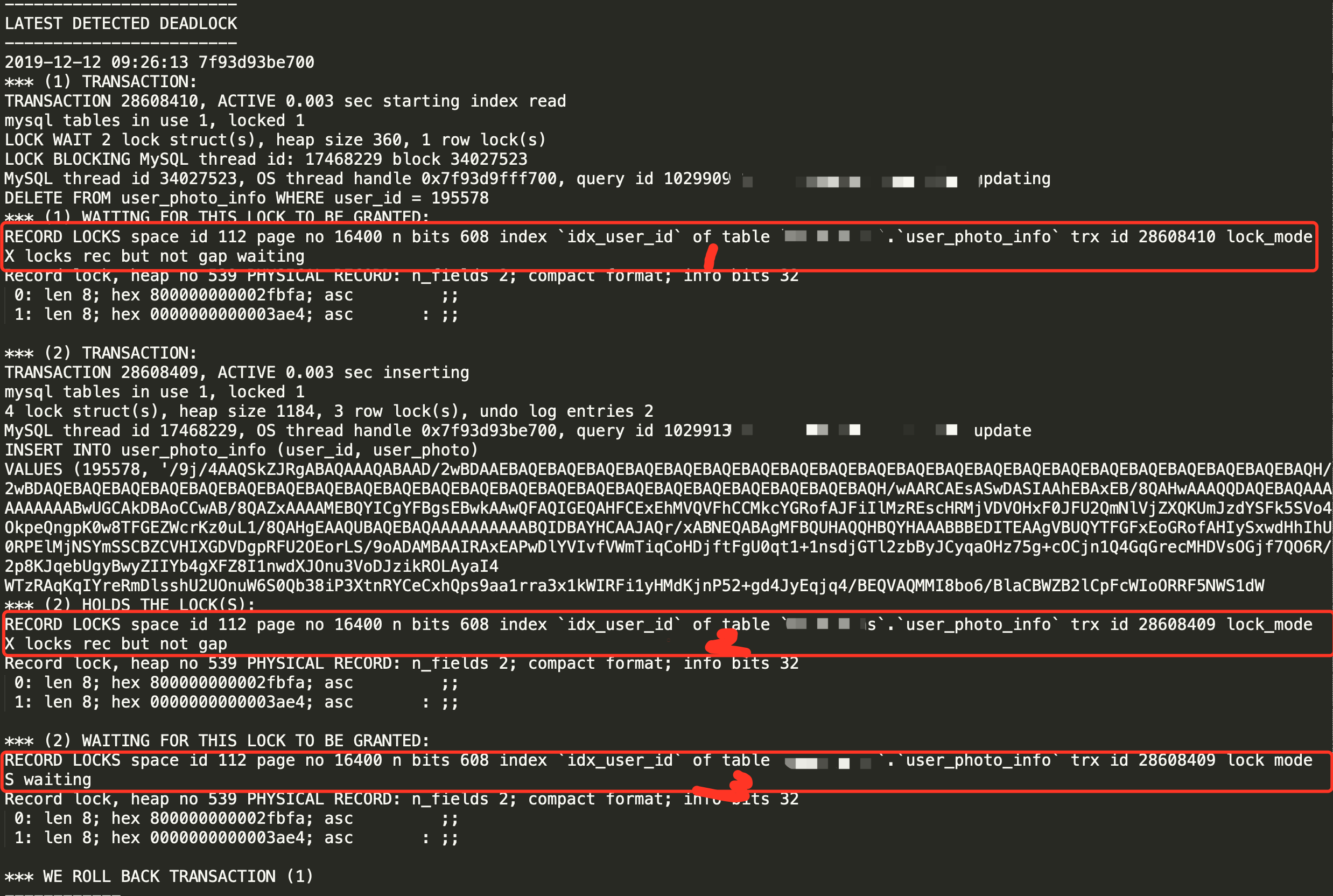
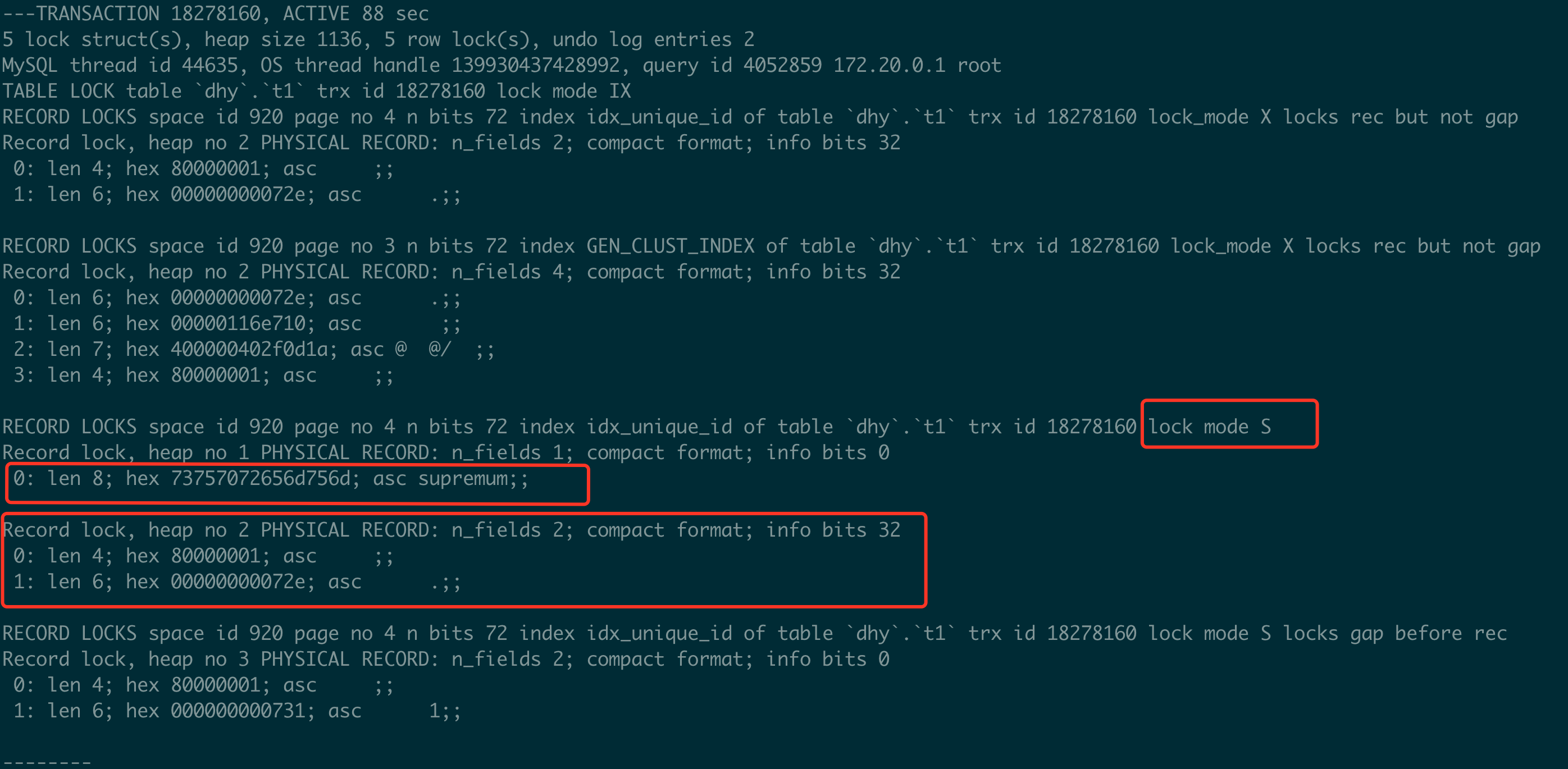
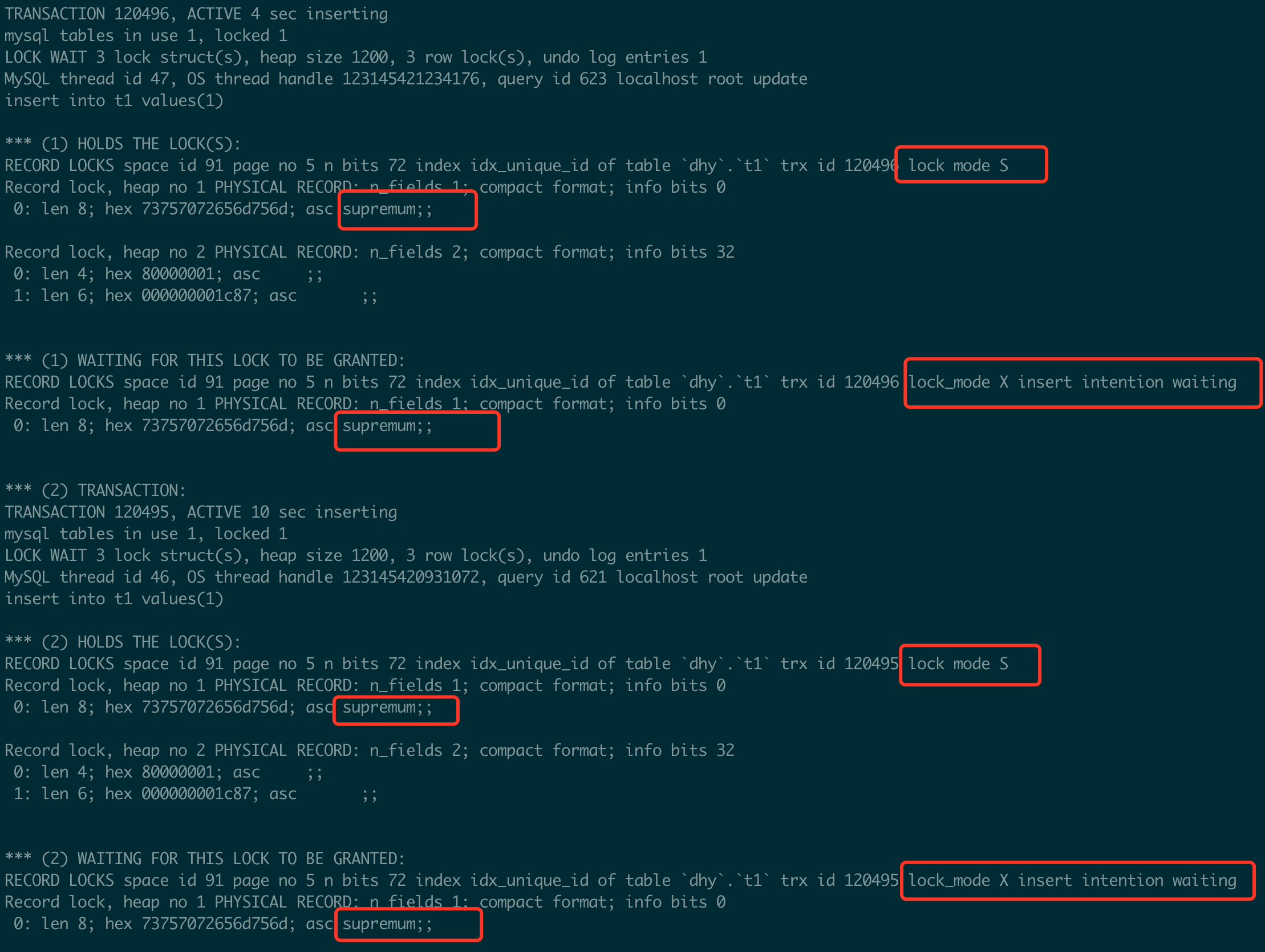
如果这里添加的不是S类型Next-Key Lock锁,会出现主键失效的情况, 假设添加的是S NOT GAP锁,情况如下:
session1 添加X类型记录锁
session2 添加S NOT GAP锁 //等待
session3 添加S NOT GAP锁 //等待
由于session1还没有提交,所以会做唯一性约束检查,申请S NOT GAP锁(假设)。当session1执行commit后,session2和session3获得S NOT GAP 锁(假设), 并且session2和session3同时会对下一条记录添加S NOT GAP 锁(假设),这时session2检查插入记录的下一条时发现有S NOT GAP锁,不与插入意向锁冲突,则插入成功,同理session3也会做相应的检查,但也不会发生冲突,所以两条记录都会插入成功。
do { 省略若干代码 const ulint lock_type = index->table->skip_gap_locks() ? LOCK_REC_NOT_GAP : LOCK_ORDINARY; //如果锁操作的表,是不允许跳过间隙锁的,则lock_type就是LOCK_ORDINARY --Next-Key Lock 省略若干代码 else { if (index->table->skip_gap_locks()) { /* Only GAP lock is possible on supremum. */ if (page_rec_is_supremum(rec)) { continue; }
switch (err) { case DB_SUCCESS_LOCKED_REC: err = DB_SUCCESS; case DB_SUCCESS: break; default: goto end_scan; }
if (page_rec_is_supremum(rec)) { continue; }
cmp = cmp_dtuple_rec(entry, rec, index, offsets);
if (cmp == 0 && !index->allow_duplicates) { if (row_ins_dupl_error_with_rec(rec, entry, index, offsets)) { // 如果冲突检测到两条记录一样,则判断下记录是否是标记为delete的,有可能记录delete了但是还没有被purge线程purge err = DB_DUPLICATE_KEY;
thr_get_trx(thr)->error_index = index;
/* If the duplicate is on hidden FTS_DOC_ID, state so in the error log */ if (index == index->table->fts_doc_id_index && DICT_TF2_FLAG_IS_SET(index->table, DICT_TF2_FTS_HAS_DOC_ID)) { ib::error(ER_IB_MSG_958) << "Duplicate FTS_DOC_ID" " value on table " << index->table->name; }
/* If another transaction has an explicit lock request which locks the gap, waiting or granted, on the successor, the insert has to wait. An exception is the case where the lock by the another transaction is a gap type lock which it placed to wait for its turn to insert. We do not consider that kind of a lock conflicting with our insert. This eliminates an unnecessary deadlock which resulted when 2 transactions had to wait for their insert. Both had waiting gap type lock requests on the successor, which produced an unnecessary deadlock. */
update survey_state set financ_requirements = 1where org_credit_code in (SELECT org_credit_code FROM answer_info a LEFTJOIN answer_detail b ON a.id = b.answer_info_id WHERE b.question_id = 'f32825fa-bd98-11e9-b26c-fa163e4c9a89'AND b.selection_id = '0d4ed3a9-bd9b-11e9-b26c-fa163e4c9a89');
以”SELECT c1, c2 FROM t1 WHERE c3 = const GROUP BY c1, c2;”这个语句为例,查看其执行计划:
1 2 3 4 5 6 7
root@localhost:mysql-8.0-3319.sock 10:32:37 [dhy]>explain SELECT c1, c2 FROM t1 WHERE c3 = 1 GROUP BY c1, c2; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+---------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+---------------------------------------+ | 1 | SIMPLE | t1 | NULL | range | idx | idx | 14 | NULL | 2 | 100.00 | Using where; Using index for group-by | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+---------------------------------------+ 1 row in set, 1warning (0.00 sec)
执行计划中Extra这列中出现了 Using index for group-by,代表使用了松散索引,但为何这个语句能用到松散索引,松散索引是到底是什么呢? 个人对松散的理解,就像是跳跃索引,”SELECT c1, c2 FROM t1 WHERE c3 = const GROUP BY c1, c2;”这个语句group by c1,c2遵循索引的”最左原则”c1,c2这两列是有序排列的,则可以先对前两列distinct,再过滤c3这个字段,这样减少了前两列的扫描次数。
紧凑索引(Tight Index Scan)
紧凑索引就像是进行了索引全表扫描,以下这两个语句不能使用松散索引,但是可以使用紧凑索引扫描:
1 2
SELECT c1, c2, c3 FROM t1 WHERE c2 = 'a'GROUPBY c1, c3; SELECT c1, c2, c3 FROM t1 WHERE c1 = 'a'GROUPBY c2, c3;
先看下执行计划:
1 2 3 4 5 6 7
root@localhost:mysql-8.0-3319.sock 11:00:42 [dhy]>explain SELECT c1, c2, c3 FROM t1 WHERE c2 = 2 GROUP BY c1, c3; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | t1 | NULL | index | idx | idx | 14 | NULL | 3 | 33.33 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+--------------------------+ 1 row in set, 1warning (0.00 sec)
这里type是index,也就是索引全表扫描,并且Extra里没有Using index for group-by,为何这里不能利用松散索引呢?因为group by字段是c1 和 c3两个字段,中间出现了GAP,所以无法按”SELECT c1, c2 FROM t1 WHERE c3 = const GROUP BY c1, c2;”这个SQL一样先distinct c1 ,c2这两个字段,因为c1,c3两个字段组合起来不一定是排序的,只能逐条扫描然后再过滤c2字段的值。例如数据是这样的:
insertinto t values (1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(3,3); 下面这两条语句是为了测试场景1中,能出现跳跃索引扫描 INSERTINTO t SELECT a, b + 5FROM t; INSERTINTO t SELECT a, b + 10FROM t;
场景1where条件后只带有组合索引的第二个字段
1 2 3 4 5 6 7
root@localhost:mysql-8.0-3319.sock 16:26:33 [dhy]> explain select a,b from t where b = 2; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+ | 1 | SIMPLE | t | NULL | range | idx_a_b | idx_a_b | 10 | NULL | 3 | 100.00 | Using where; Using index for skip scan | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+----------------------------------------+ 1 row inset, 1 warning (0.00 sec)
从执行计划中可以看到,key这列显示使用到索引,同时key_ley的长度是10,也就是使用到了组合索引的所有字段,Extra中显示走了跳跃索引扫描(Using index for skip scan),如果是8.0以下的版本则不会出现跳跃索引,而是索引全表扫描。 这里执行时的流程应该是如下发生:
获取组合索引中,第一列去重之后的第一个值(本例子中就是a=1)
根据此值与组合索引中的第二列构成一个查询条件(a=1 and b = 2)
执行查询
获取组合索引中,第一列去重之后的第二个值(本例子中就是a=2)
根据此值与组合索引中的第二列构成一个查询条件(a=2 and b = 2)
执行查询
反复按以上规则执行,直到第一列去重之后的值全部扫描完成
场景2where条件后第一列是范围查询
1 2 3 4 5 6 7
mysql> explain select * from t where a > 1 and b = 2; +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ | 1 | SIMPLE | t | NULL | range | idx_a_b | idx_a_b | 5 | NULL | 6 | 11.11 | Using where; Using index | +----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+--------------------------+ 1 row inset, 1 warning (0.00 sec)
oot@localhost:mysql-8.0-3319.sock 22:07:57 [dhy]>explain format=tree select * from t where a > 1 order by b ; +---------------------------------------------------------------------------------------+ | EXPLAIN | +---------------------------------------------------------------------------------------+ | -> Sort: t.b -> Filter: (t.a > 1) -> Index range scan on t using idx_a_b | +---------------------------------------------------------------------------------------+ 1 row inset (0.00 sec)
先根据索引做范围查询,过滤掉不满足条件(a>1)的数据,然后在根据b字段排序
场景3where条件后第一列是等值查询
1 2 3 4 5 6 7
mysql> explain select * from t where a =1 and b = 2 ; +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+ | 1 | SIMPLE | t | NULL | ref | idx_a_b | idx_a_b | 10 | const,const | 1 | 100.00 | Using index | +----+-------------+-------+------------+------+---------------+---------+---------+-------------+------+----------+-------------+ 1 row inset, 1 warning (0.00 sec)